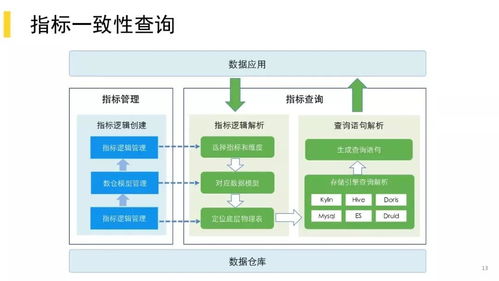
在当今信息爆炸的时代,数据已成为驱动社会运转和科技创新的核心燃料。全球科技巨头谷歌,作为数据处理的先驱与典范,其背后支撑着数十亿用户请求、PB级数据吞吐的“大数据架构”,一直是业界研究与效仿的焦点。本文将深入探秘谷歌的大数据处理机制,解析其如何构建高效、可靠、可扩展的数据处理服务体系。
一、核心基石:谷歌文件系统(GFS)与分布式存储
一切海量数据处理的起点是存储。谷歌早期研发的谷歌文件系统(Google File System, GFS)奠定了其大数据架构的基石。GFS是一个专为大规模、分布式、数据密集型应用设计的可扩展分布式文件系统。它将文件分割成固定大小的块(Chunks),并分布存储在上千台普通的商用服务器上,通过多副本机制确保数据的可靠性与高可用性。这种设计理念——即用软件层面的智能来弥补硬件层面的不可靠——深刻影响了后续如Hadoop HDFS等开源系统的发展。
二、计算引擎:从MapReduce到新一代数据处理范式
有了海量数据的存储,下一步是如何高效计算。谷歌在2004年公开的MapReduce编程模型,革命性地简化了大规模数据集(如网页索引、日志分析)的并行处理。它将计算任务抽象为“Map”(映射)和“Reduce”(归约)两个阶段,由系统自动处理分布式执行、容错和负载均衡,使开发人员无需关心底层复杂的分布式细节。
随着数据处理需求日益复杂(如迭代计算、流处理),MapReduce在延迟和灵活性上的局限性逐渐显现。为此,谷歌相继推出了更强大的数据处理范式:
- FlumeJava:一个用于构建复杂、高效数据管道的Java库,它会在后端将管道操作优化并编译成一系列MapReduce作业执行。
- MillWheel 与 Dataflow/Beam 模型:为了满足低延迟的流处理需求,谷歌开发了MillWheel这样的流处理系统。谷歌将其批处理和流处理的经验抽象整合,提出了统一的“Dataflow”编程模型(后贡献给Apache Beam项目)。该模型的核心思想是将数据视为在时间维度上持续更新的集合,并提供了“事件时间”处理、窗口化、触发器等高阶抽象,真正实现了批流一体。
三、数据管理与服务:Bigtable、Spanner与BigQuery
高效的处理离不开高效的数据组织与管理。
- Bigtable:这是一个分布式的、稀疏的、多维排序的映射表,用于管理结构化数据。它构建在GFS之上,能够支撑从PB级数据到每秒百万次操作的服务。Bigtable的设计(如SSTable存储格式、MemTable与SSTable的多级结构)为HBase等NoSQL数据库提供了蓝图。
- Spanner:随着全球业务对强一致性和全球分布的需求,谷歌开发了Spanner——一个全球分布的、支持同步复制的、关系型数据库服务。它首次在全球规模下实现了外部一致性(通过TrueTime API),是“NewSQL”的典范。
- BigQuery:作为对外提供的数据分析服务,BigQuery完美体现了谷歌大数据架构的威力。它是一个完全托管、无需运维的云数据仓库。用户只需传入SQL查询,BigQuery便能利用其底层强大的分布式执行引擎(Dremel,采用列式存储和树状查询架构)在数秒内分析TB甚至PB级的数据。它将复杂的集群管理、资源调度和查询优化完全封装为服务,让数据分析触手可及。
四、资源调度与协调:Borg/Omega 与 Kubernetes
要让成千上万的数据处理任务在庞大的服务器集群中有序、高效地运行,一个顶级的资源调度与集群管理系统至关重要。谷歌内部长期使用Borg系统(及其下一代Omega)来管理其数据中心的所有工作负载。Borg负责进行细粒度的资源打包、调度、管理和故障恢复。其开源版本的核心思想最终演化成了当今容器编排的事实标准——Kubernetes。正是这样的系统,确保了数据处理作业能够像使用一台超级计算机一样使用整个数据中心的海量资源。
五、数据处理服务的演进:从基础设施到云平台
纵观谷歌大数据架构的演进,其核心理念经历了从“构建强大基础设施”到“提供极致简化服务”的转变。早期的GFS、MapReduce、Bigtable是工程师手中的强大工具,但使用门槛高。而如今的Google Cloud Platform(GCP)上的数据处理服务,如Cloud Dataflow(实现Dataflow模型)、BigQuery、Cloud Spanner、Pub/Sub等,则将底层架构的复杂性彻底隐藏。开发者只需关注业务逻辑和数据价值,而无需操心集群规模、资源扩缩容和系统运维。这种“服务化”(Serverless)的思维,正是大数据处理未来发展的明确方向。
###
谷歌的大数据架构并非一成不变的静态系统,而是一个持续演进、不断解决新挑战的有机体。从GFS、MapReduce的奠基,到Bigtable、Spanner的数据管理革新,再到Dataflow模型的范式统一,以及最终通过云平台将一切转化为易用的服务,这条路径清晰地展示了海量数据处理技术的演进逻辑:在确保可扩展性、可靠性的基础上,不断追求更高的效率、更低的延迟、更强的语义一致性,并最终致力于极致地降低使用门槛,释放数据潜能。 探秘其架构,不仅是为了理解技术的精妙,更是为了洞察数据驱动未来的方向。